
2021
02-21
02-21
python爬虫scrapy基于CrawlSpider类的全站数据爬取示例解析
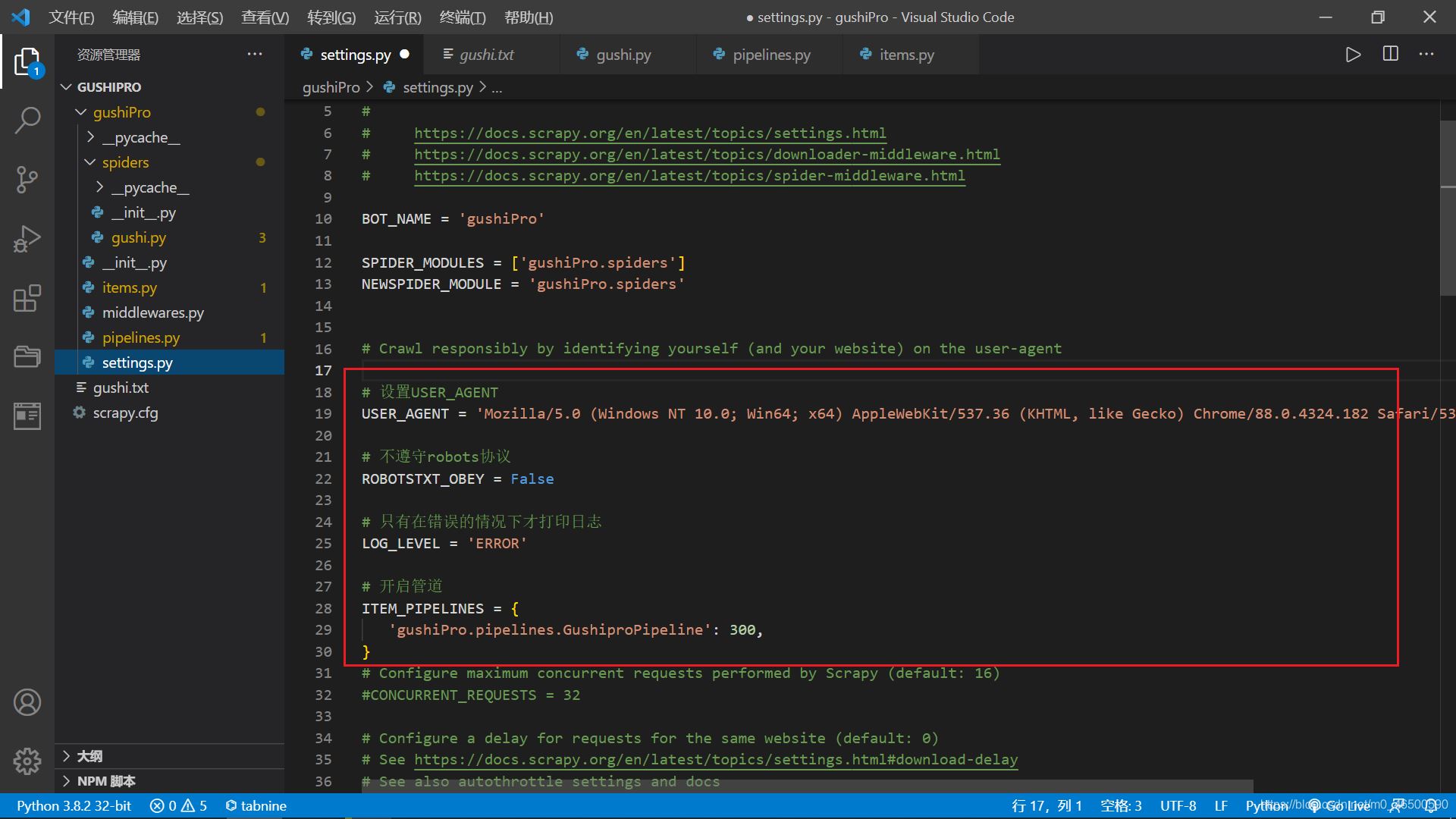 一、CrawlSpider类介绍1.1引入使用scrapy框架进行全站数据爬取可以基于Spider类,也可以使用接下来用到的CrawlSpider类。基于Spider类的全站数据爬取之前举过栗子,感兴趣的可以康康scrapy基于CrawlSpider类的全站数据爬取1.2介绍和使用1.2.1介绍CrawlSpider是Spider的一个子类,因此CrawlSpider除了继承Spider的特性和功能外,还有自己特有的功能,主要用到的是LinkExtractor()和rules=(Rule(LinkExtractor(allow=r'Items/'...
继续阅读 >
一、CrawlSpider类介绍1.1引入使用scrapy框架进行全站数据爬取可以基于Spider类,也可以使用接下来用到的CrawlSpider类。基于Spider类的全站数据爬取之前举过栗子,感兴趣的可以康康scrapy基于CrawlSpider类的全站数据爬取1.2介绍和使用1.2.1介绍CrawlSpider是Spider的一个子类,因此CrawlSpider除了继承Spider的特性和功能外,还有自己特有的功能,主要用到的是LinkExtractor()和rules=(Rule(LinkExtractor(allow=r'Items/'...
继续阅读 >